OneRouter supports Claude Code
How Kimi-K2-Thinking Stays Stable in Long Tasks with Claude Code

Date
Dec 15, 2025
Author
Andrew Zheng
Developers and researchers today face three major challenges when selecting large language models: sustaining long-horizon reasoning, managing context limits, and controlling operational costs. Traditional closed models like Claude Sonnet 4 and GPT-5 offer strong performance but become costly and constrained when handling multi-step or tool-based workflows.
This article introduces Kimi-K2-Thinking—an open, agent-oriented alternative that combines step-by-step reasoning, dynamic tool integration, and massive context capacity. Through comparisons, benchmarks, and setup guides, it explains how Kimi-K2 solves the pain points of coherence, scale, and affordability in long, complex AI tasks.
What Advantages Does Kimi-K2-Thinking Have?
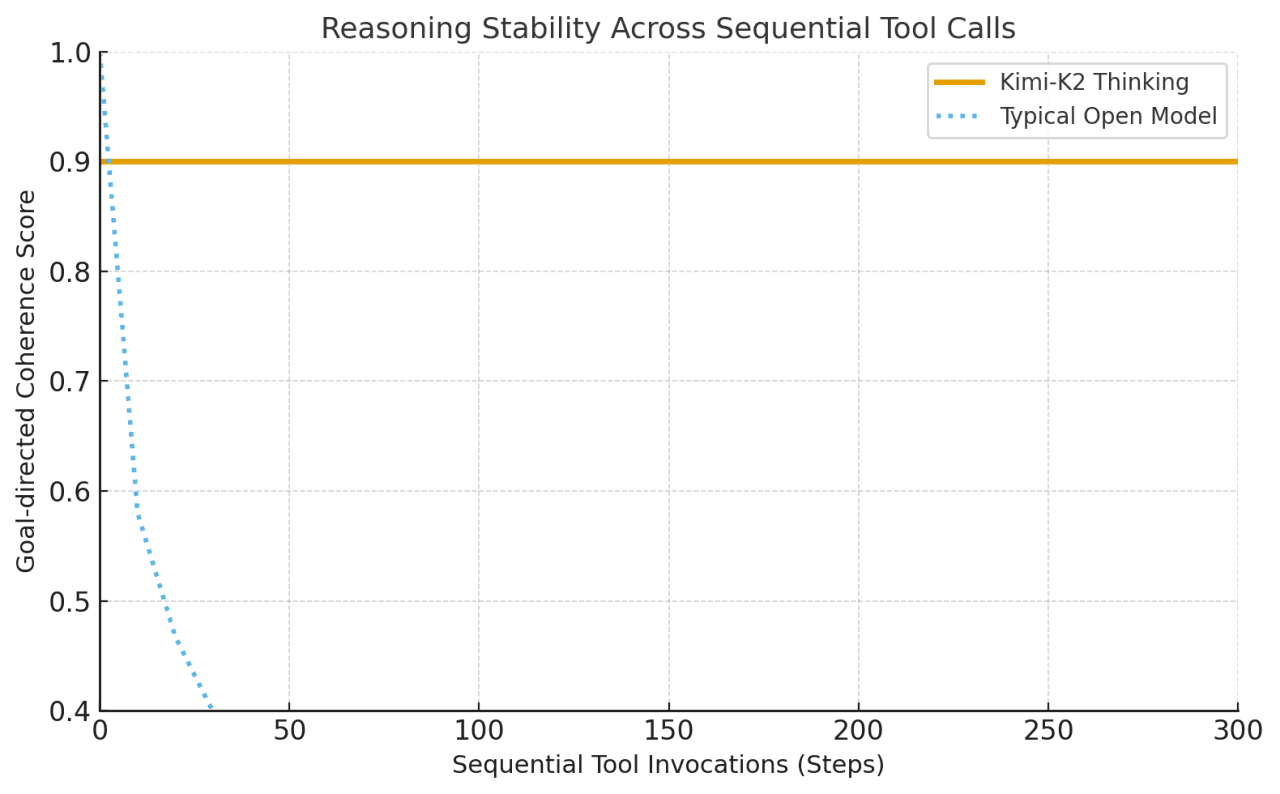
Kimi-K2 Thinking was built as a “thinking agent” that interleaves step-by-step Chain-of-Thought reasoning with dynamic function/tool calls. Unlike typical models that may drift or lose coherence after a few tool uses, Kimi-K2 maintains stable goal-directed behavior across 200–300 sequential tool invocations without human intervention.
This is a major leap: prior open models tended to degrade after 30–50 steps. In other words, Kimi-K2 can handle hundreds of execute steps in one session while staying on track to solve complex problems.
Anthropic’s Claude was previously known for such “interleaved thinking” with tools, but Kimi-K2 brings this capability to the open-source realm
The architecture balances scale, efficiency, and stability—allowing Kimi-K2-Thinking to sustain complex, tool-rich reasoning over long sequences.
Architecture Feature | Practical Advantage |
|---|---|
Mixture-of-Experts (MoE) | Expands model capacity without increasing cost; selects the most relevant experts for each task. |
1T parameters / 32B activated | Combines large-scale knowledge with efficient computation. |
61 layers with 1 dense layer | Keeps reasoning deep yet coherent across steps. |
384 experts, 8 active per token | Improves specialization and adaptability to diverse problems. |
256K context length | Processes very long inputs and maintains continuity in long reasoning chains. |
MLA (Multi-Head Latent Attention) | Strengthens long-range focus and reduces memory load. |
SwiGLU activation | Stabilizes training and supports smooth, precise reasoning. |
Which Model Performs Better, Kimi-K2-Thinking or Sonnet 4?
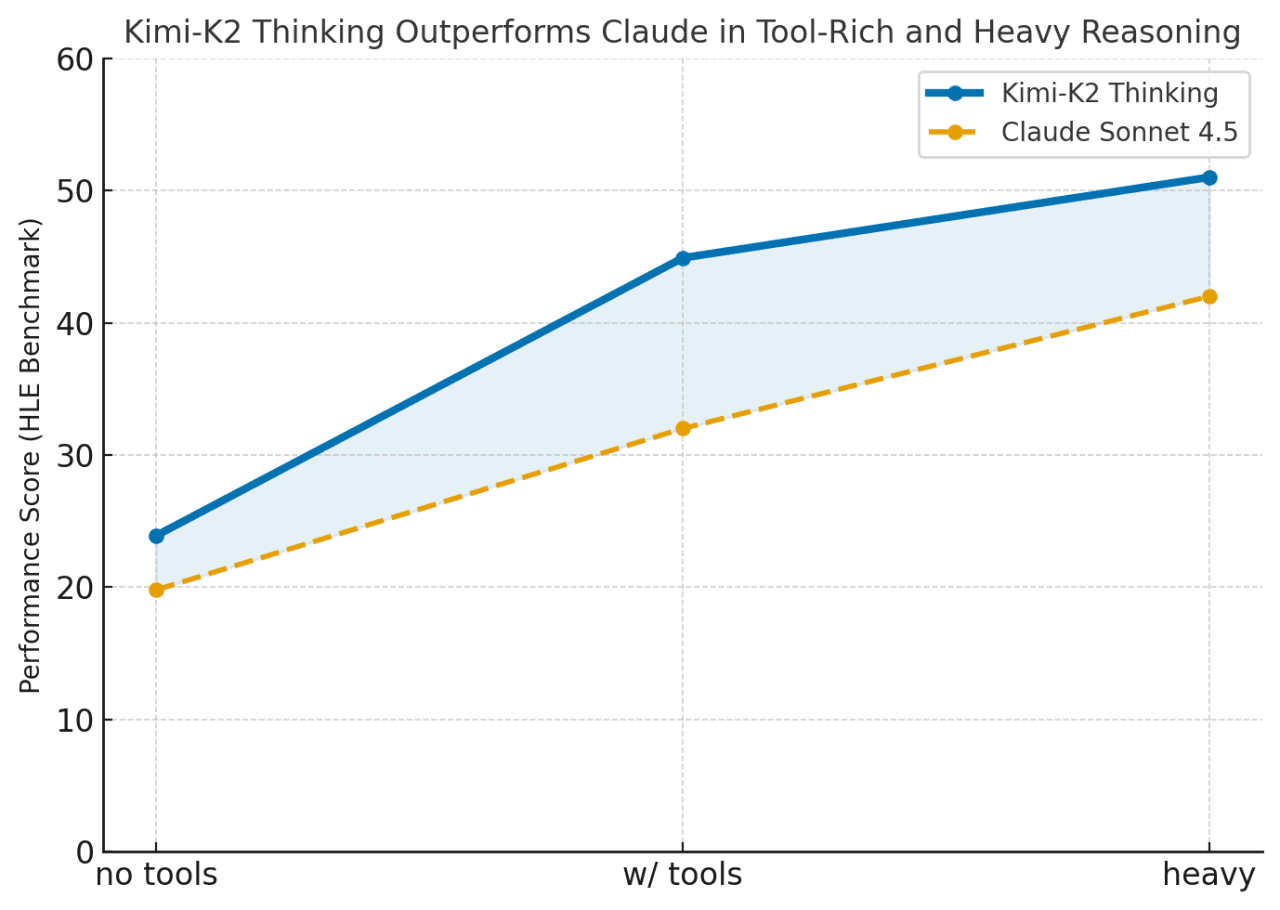
Kimi-K2 performs close to GPT-5 and Claude on major math benchmarks, but it is slightly behind GPT-5 and Claude in MMLU-Pro/Redux, Longform Writing and Code.
Kimi-K2 outperforms when tools are enabled or tasks require long chained reasoning (HLE w/ tools = 44.9 vs Claude 32.0). It bridges the gap between closed models like Claude and open-source systems, excelling in sustained, tool-rich problem solving.
Category | Benchmark | Setting | Kimi K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | Kimi K2 0905 | DeepSeek-V3.2 | Grok-4 |
|---|---|---|---|---|---|---|---|---|
Reasoning / Math | HLE | no tools | 23.9 | 26.3 | 19.8 | 7.9 | 19.8 | 25.4 |
HLE | w/ tools | 44.9 | 41.7 | 32.0 | 21.7 | 20.3 | 41.0 | |
HLE | heavy | 51.0 | 42.0 | – | – | – | 50.7 | |
AIME25 | no tools | 94.5 | 94.6 | 87.0 | 51.0 | 89.3 | 91.7 | |
AIME25 | w/ python | 99.1 | 99.6 | 100.0 | 75.2 | 58.1 | 98.8 | |
AIME25 | heavy | 100.0 | 100.0 | – | – | – | 100.0 | |
HMMT25 | no tools | 89.4 | 93.3 | 74.6 | 38.8 | 83.6 | 90.0 | |
HMMT25 | w/ python | 95.1 | 96.7 | 88.8 | 70.4 | 49.5 | 93.9 | |
HMMT25 | heavy | 97.5 | 100.0 | – | – | – | 96.7 | |
IMO-AnswerBench | no tools | 78.6 | 76.0 | 65.9 | 45.8 | 76.0 | 73.1 | |
GPQA | no tools | 84.5 | 85.7 | 83.4 | 74.2 | 79.9 | 87.5 | |
General Tasks | MMLU-Pro | no tools | 84.6 | 87.1 | 87.5 | 81.9 | 85.0 | – |
MMLU-Redux | no tools | 94.4 | 95.3 | 95.6 | 92.7 | 93.7 | – | |
Longform Writing | no tools | 73.8 | 71.4 | 79.8 | 62.8 | 72.5 | – | |
HealthBench | no tools | 58.0 | 67.2 | 44.2 | 43.8 | 46.9 | – | |
Agentic Search | BrowseComp | w/ tools | 60.2 | 54.9 | 24.1 | 7.4 | 40.1 | – |
BrowseComp-ZH | w/ tools | 62.3 | 63.0 | 42.4 | 22.2 | 47.9 | – | |
Seal-0 | w/ tools | 56.3 | 51.4 | 53.4 | 25.2 | 38.5 | – | |
FinSearchComp-T3 | w/ tools | 47.4 | 48.5 | 44.0 | 10.4 | 27.0 | – | |
Frames | w/ tools | 87.0 | 86.0 | 85.0 | 58.1 | 80.2 | – | |
Coding Tasks | SWE-bench Verified | w/ tools | 71.3 | 74.9 | 77.2 | 69.2 | 67.8 | – |
SWE-bench Multilingual | w/ tools | 61.1 | 55.3 | 68.0 | 55.9 | 57.9 | – | |
Multi-SWE-bench | w/ tools | 41.9 | 39.3 | 44.3 | 33.5 | 30.6 | – | |
SciCode | no tools | 44.8 | 42.9 | 44.7 | 30.7 | 37.7 | – | |
LiveCodeBench V6 | no tools | 83.1 | 87.0 | 64.0 | 56.1 | 74.1 | – | |
OJ-Bench (cpp) | no tools | 48.7 | 56.2 | 30.4 | 25.5 | 38.2 | – | |
Terminal-Bench | w/ simulated tools (JSON) | 47.1 | 43.8 | 51.0 | 44.5 | – | – |
no tools: pure language reasoning, no external tools.
w/ tools: can call external tools (e.g., search, code).
w/ python: uses only Python for computation.
w/ simulated tools (JSON): simulates tool calls in JSON format.
heavy: high-intensity, long-chain reasoning test.
How Large Is the Cost Gap Between Kimi-K2-Thinking and Claude Sonnet 4?
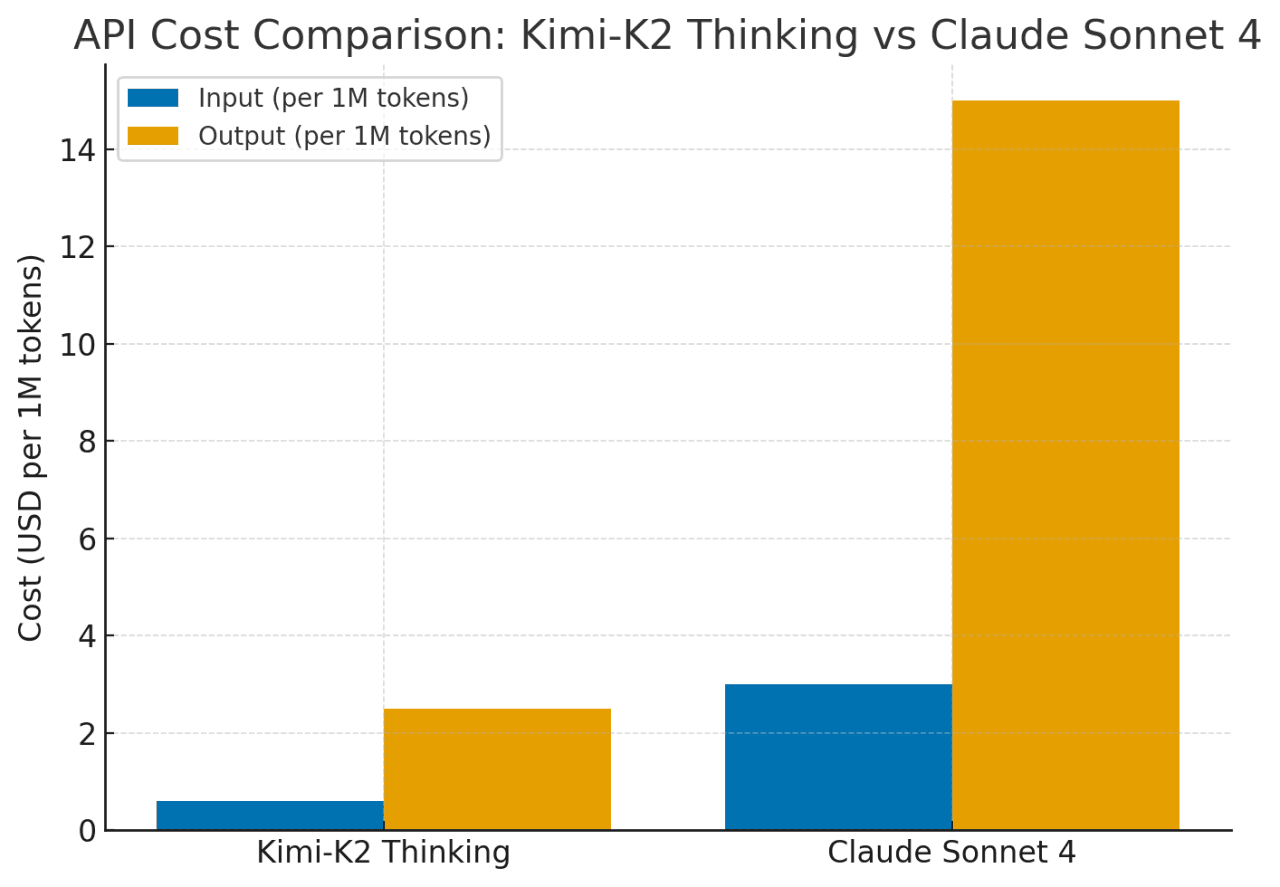
Kimi-K2 delivers similar capabilities to Claude Sonnet 4 at roughly 75–80% lower cost. Its pricing stays flat even for long contexts (up to 256K tokens) or frequent tool use, while Claude’s costs rise sharply for extended contexts and agent actions. In short, Kimi-K2 offers Claude/GPT-level performance with far better cost efficiency for complex, long-horizon reasoning tasks.
How to Use Kimi-K2-Thinking in Claude Code?
OneRouter currently offers the most affordable full-context Kimi-K2-Thinking API.
OneRouter provides APIs with 262K context, and costs of $0.6/input and $2.5/output, supporting structured output and function calling, which delivers strong support for maximizing Kimi K2 Thinking's code agent potential.

Use Kimi-K2-Thinking with Claude Code
Now, OneRouter provides Anthropic SDK compatible LLM API services, enabling you to easily use OneRouter LLM models in Claude Code to complete tasks. Please refer to the guide below to complete the integration process.
1. Setup your OneRouter account & API keys
The first step to start using OneRouter is to create an account and get your API key.
2. Install Claude Code
Before installing Claude Code, please ensure your local environment has Node.js 18 or higher installed.
To install Claude Code, run the following command:
npm install -g @anthropic-ai/claude-code
3. Setup the Claude Code configuration
Open the terminal and set up environment variables as follows:
# Set the Anthropic SDK compatible API endpoint provided by OneRouter. export ANTHROPIC_BASE_URL="https://llm.onerouter.pro" export ANTHROPIC_AUTH_TOKEN="<OneRouter API Key>" # Set the model provided by OneRouter. export ANTHROPIC_MODEL="kimi-k2-thinking" export ANTHROPIC_SMALL_FAST_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_OPUS_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_SONNET_MODEL="kimi-k2-thinking"
4. Start your first session
Next, navigate to your project directory and start Claude Code. You will see the Claude Code prompt inside a new interactive session:
cd <your-project-directory> claude
How Can Enable Quick Switching Between Claude, GLM, and Kimi Models?
OneRouter General Conversion Layer lets you run the Claude Agent SDK against any model in OneRouter—without changing your agent logic.
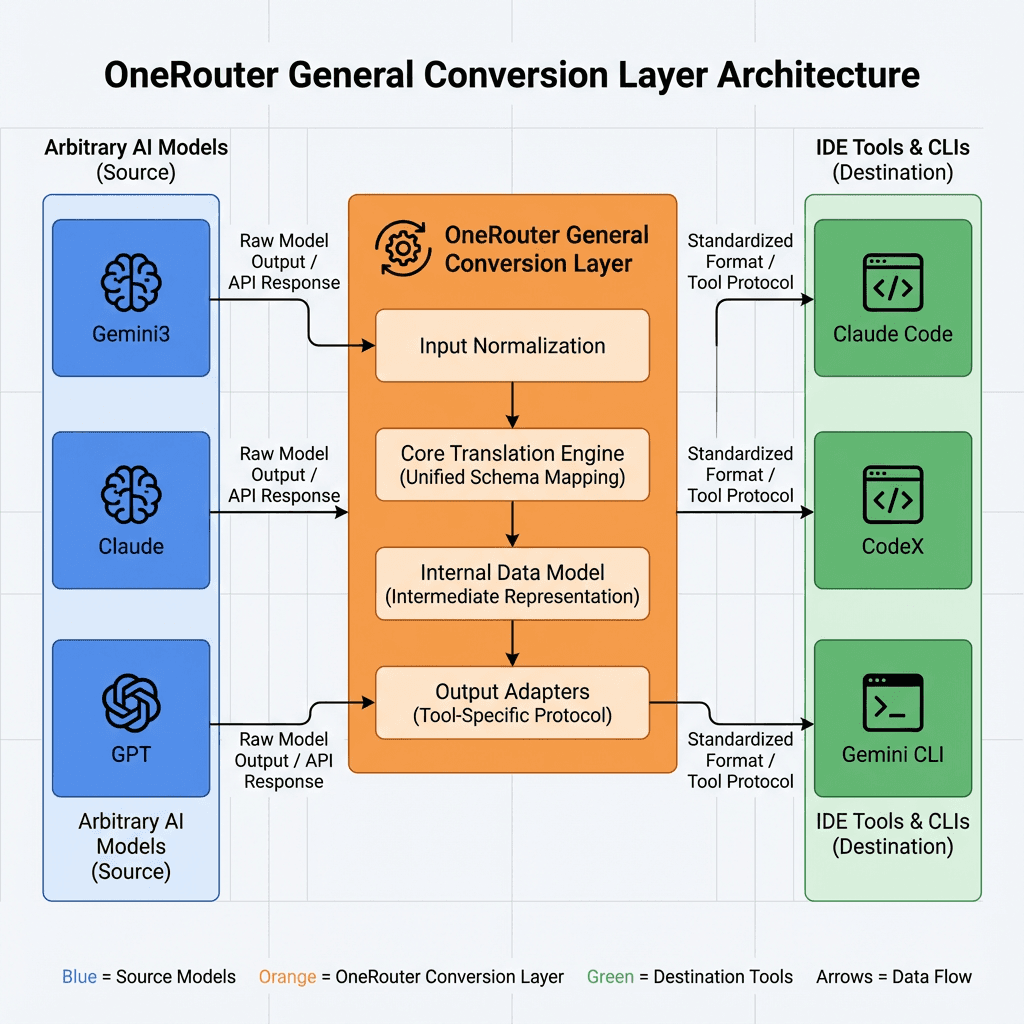
With the OneRouter General Conversion Layer, developers can keep using the same SDK APIs. The conversion layer translates Anthropic-style Messages requests to whichever upstream (Anthropic、OpenAI or other models in OneRouter) matches the model string you provide.
Under What Conditions Should Developers Switch to Kimi-K2-Thinking?
When to Use Kimi-K2 Thinking — Task Characteristics and Matching Strengths
1. Long-Horizon / Agentic Tasks
Task traits: multi-step workflows, autonomous tool calls, continuous reasoning (e.g., research assistants, data-mining agents, or auto-coders).
Kimi-K2 solves: maintains coherent reasoning across hundreds of steps; integrates planning, searching, and coding without drifting—where GPT-5 or Claude may lose focus over long sequences.
2. Large-Context Tasks
Task traits: require feeding long documents, full codebases, or multi-file inputs at once.
Kimi-K2 solves: offers a native 256 K token context with flat pricing; processes massive input without chunking or the high long-context fees seen in Claude or GPT-4.
3. Cost-Sensitive Deployments
Task traits: large-scale runs or tight budgets (millions of tokens daily).
Kimi-K2 solves: delivers Claude/GPT-level reasoning at roughly 4–6× lower cost, making advanced reasoning affordable for startups and sustained workloads.
4. Domain Benchmark Parity
Task traits: complex reasoning, structured QA, or mathematical logic where closed models used to dominate.
Kimi-K2 solves: matches or exceeds GPT-5 and Claude 4.5 on AIME, HMMT, and GPQA Diamond, proving that open models can now perform at frontier levels in reasoning-heavy domains.
Kimi-K2-Thinking bridges the gap between closed proprietary systems and open innovation. It delivers near-Claude performance with 75–80% lower cost, supports 256K context windows, and sustains hundreds of reasoning or tool-use steps without drift. For developers needing deep reasoning, agentic workflows, or open-source deployment, Kimi-K2 offers a practical, scalable, and transparent solution that redefines cost-efficiency in advanced AI reasoning.
Frequently Asked Questions
What makes Kimi-K2-Thinking different from Claude Sonnet 4?
Kimi-K2 maintains coherent reasoning across 200–300 tool calls and costs up to 5× less, while Claude Sonnet 4’s price rises sharply with longer contexts and tool actions.
Is Kimi-K2-Thinking suitable for coding?
Yes. It can write and debug code effectively, but it performs best on reasoning-heavy or multi-step tool-driven projects rather than simple one-shot coding.
How large is Kimi-K2-Thinking’s context window?
It supports 256K tokens by default, enabling full codebase or document reasoning in one pass—without the premium long-context charges found in Claude or GPT models.
OneRouter provides a unified API that gives you access to hundreds of AI models through a single endpoint, while automatically handling fallbacks and selecting the most cost-effective options. Get started with just a few lines of code using your preferred SDK or framework.
Developers and researchers today face three major challenges when selecting large language models: sustaining long-horizon reasoning, managing context limits, and controlling operational costs. Traditional closed models like Claude Sonnet 4 and GPT-5 offer strong performance but become costly and constrained when handling multi-step or tool-based workflows.
This article introduces Kimi-K2-Thinking—an open, agent-oriented alternative that combines step-by-step reasoning, dynamic tool integration, and massive context capacity. Through comparisons, benchmarks, and setup guides, it explains how Kimi-K2 solves the pain points of coherence, scale, and affordability in long, complex AI tasks.
What Advantages Does Kimi-K2-Thinking Have?
Kimi-K2 Thinking was built as a “thinking agent” that interleaves step-by-step Chain-of-Thought reasoning with dynamic function/tool calls. Unlike typical models that may drift or lose coherence after a few tool uses, Kimi-K2 maintains stable goal-directed behavior across 200–300 sequential tool invocations without human intervention.
This is a major leap: prior open models tended to degrade after 30–50 steps. In other words, Kimi-K2 can handle hundreds of execute steps in one session while staying on track to solve complex problems.
Anthropic’s Claude was previously known for such “interleaved thinking” with tools, but Kimi-K2 brings this capability to the open-source realm
The architecture balances scale, efficiency, and stability—allowing Kimi-K2-Thinking to sustain complex, tool-rich reasoning over long sequences.
Architecture Feature | Practical Advantage |
|---|---|
Mixture-of-Experts (MoE) | Expands model capacity without increasing cost; selects the most relevant experts for each task. |
1T parameters / 32B activated | Combines large-scale knowledge with efficient computation. |
61 layers with 1 dense layer | Keeps reasoning deep yet coherent across steps. |
384 experts, 8 active per token | Improves specialization and adaptability to diverse problems. |
256K context length | Processes very long inputs and maintains continuity in long reasoning chains. |
MLA (Multi-Head Latent Attention) | Strengthens long-range focus and reduces memory load. |
SwiGLU activation | Stabilizes training and supports smooth, precise reasoning. |
Which Model Performs Better, Kimi-K2-Thinking or Sonnet 4?
Kimi-K2 performs close to GPT-5 and Claude on major math benchmarks, but it is slightly behind GPT-5 and Claude in MMLU-Pro/Redux, Longform Writing and Code.
Kimi-K2 outperforms when tools are enabled or tasks require long chained reasoning (HLE w/ tools = 44.9 vs Claude 32.0). It bridges the gap between closed models like Claude and open-source systems, excelling in sustained, tool-rich problem solving.
Category | Benchmark | Setting | Kimi K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | Kimi K2 0905 | DeepSeek-V3.2 | Grok-4 |
|---|---|---|---|---|---|---|---|---|
Reasoning / Math | HLE | no tools | 23.9 | 26.3 | 19.8 | 7.9 | 19.8 | 25.4 |
HLE | w/ tools | 44.9 | 41.7 | 32.0 | 21.7 | 20.3 | 41.0 | |
HLE | heavy | 51.0 | 42.0 | – | – | – | 50.7 | |
AIME25 | no tools | 94.5 | 94.6 | 87.0 | 51.0 | 89.3 | 91.7 | |
AIME25 | w/ python | 99.1 | 99.6 | 100.0 | 75.2 | 58.1 | 98.8 | |
AIME25 | heavy | 100.0 | 100.0 | – | – | – | 100.0 | |
HMMT25 | no tools | 89.4 | 93.3 | 74.6 | 38.8 | 83.6 | 90.0 | |
HMMT25 | w/ python | 95.1 | 96.7 | 88.8 | 70.4 | 49.5 | 93.9 | |
HMMT25 | heavy | 97.5 | 100.0 | – | – | – | 96.7 | |
IMO-AnswerBench | no tools | 78.6 | 76.0 | 65.9 | 45.8 | 76.0 | 73.1 | |
GPQA | no tools | 84.5 | 85.7 | 83.4 | 74.2 | 79.9 | 87.5 | |
General Tasks | MMLU-Pro | no tools | 84.6 | 87.1 | 87.5 | 81.9 | 85.0 | – |
MMLU-Redux | no tools | 94.4 | 95.3 | 95.6 | 92.7 | 93.7 | – | |
Longform Writing | no tools | 73.8 | 71.4 | 79.8 | 62.8 | 72.5 | – | |
HealthBench | no tools | 58.0 | 67.2 | 44.2 | 43.8 | 46.9 | – | |
Agentic Search | BrowseComp | w/ tools | 60.2 | 54.9 | 24.1 | 7.4 | 40.1 | – |
BrowseComp-ZH | w/ tools | 62.3 | 63.0 | 42.4 | 22.2 | 47.9 | – | |
Seal-0 | w/ tools | 56.3 | 51.4 | 53.4 | 25.2 | 38.5 | – | |
FinSearchComp-T3 | w/ tools | 47.4 | 48.5 | 44.0 | 10.4 | 27.0 | – | |
Frames | w/ tools | 87.0 | 86.0 | 85.0 | 58.1 | 80.2 | – | |
Coding Tasks | SWE-bench Verified | w/ tools | 71.3 | 74.9 | 77.2 | 69.2 | 67.8 | – |
SWE-bench Multilingual | w/ tools | 61.1 | 55.3 | 68.0 | 55.9 | 57.9 | – | |
Multi-SWE-bench | w/ tools | 41.9 | 39.3 | 44.3 | 33.5 | 30.6 | – | |
SciCode | no tools | 44.8 | 42.9 | 44.7 | 30.7 | 37.7 | – | |
LiveCodeBench V6 | no tools | 83.1 | 87.0 | 64.0 | 56.1 | 74.1 | – | |
OJ-Bench (cpp) | no tools | 48.7 | 56.2 | 30.4 | 25.5 | 38.2 | – | |
Terminal-Bench | w/ simulated tools (JSON) | 47.1 | 43.8 | 51.0 | 44.5 | – | – |
no tools: pure language reasoning, no external tools.
w/ tools: can call external tools (e.g., search, code).
w/ python: uses only Python for computation.
w/ simulated tools (JSON): simulates tool calls in JSON format.
heavy: high-intensity, long-chain reasoning test.
How Large Is the Cost Gap Between Kimi-K2-Thinking and Claude Sonnet 4?
Kimi-K2 delivers similar capabilities to Claude Sonnet 4 at roughly 75–80% lower cost. Its pricing stays flat even for long contexts (up to 256K tokens) or frequent tool use, while Claude’s costs rise sharply for extended contexts and agent actions. In short, Kimi-K2 offers Claude/GPT-level performance with far better cost efficiency for complex, long-horizon reasoning tasks.
How to Use Kimi-K2-Thinking in Claude Code?
OneRouter currently offers the most affordable full-context Kimi-K2-Thinking API.
OneRouter provides APIs with 262K context, and costs of $0.6/input and $2.5/output, supporting structured output and function calling, which delivers strong support for maximizing Kimi K2 Thinking's code agent potential.
Use Kimi-K2-Thinking with Claude Code
Now, OneRouter provides Anthropic SDK compatible LLM API services, enabling you to easily use OneRouter LLM models in Claude Code to complete tasks. Please refer to the guide below to complete the integration process.
1. Setup your OneRouter account & API keys
The first step to start using OneRouter is to create an account and get your API key.
2. Install Claude Code
Before installing Claude Code, please ensure your local environment has Node.js 18 or higher installed.
To install Claude Code, run the following command:
npm install -g @anthropic-ai/claude-code
3. Setup the Claude Code configuration
Open the terminal and set up environment variables as follows:
# Set the Anthropic SDK compatible API endpoint provided by OneRouter. export ANTHROPIC_BASE_URL="https://llm.onerouter.pro" export ANTHROPIC_AUTH_TOKEN="<OneRouter API Key>" # Set the model provided by OneRouter. export ANTHROPIC_MODEL="kimi-k2-thinking" export ANTHROPIC_SMALL_FAST_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_OPUS_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_SONNET_MODEL="kimi-k2-thinking"
4. Start your first session
Next, navigate to your project directory and start Claude Code. You will see the Claude Code prompt inside a new interactive session:
cd <your-project-directory> claude
How Can Enable Quick Switching Between Claude, GLM, and Kimi Models?
OneRouter General Conversion Layer lets you run the Claude Agent SDK against any model in OneRouter—without changing your agent logic.
With the OneRouter General Conversion Layer, developers can keep using the same SDK APIs. The conversion layer translates Anthropic-style Messages requests to whichever upstream (Anthropic、OpenAI or other models in OneRouter) matches the model string you provide.
Under What Conditions Should Developers Switch to Kimi-K2-Thinking?
When to Use Kimi-K2 Thinking — Task Characteristics and Matching Strengths
1. Long-Horizon / Agentic Tasks
Task traits: multi-step workflows, autonomous tool calls, continuous reasoning (e.g., research assistants, data-mining agents, or auto-coders).
Kimi-K2 solves: maintains coherent reasoning across hundreds of steps; integrates planning, searching, and coding without drifting—where GPT-5 or Claude may lose focus over long sequences.
2. Large-Context Tasks
Task traits: require feeding long documents, full codebases, or multi-file inputs at once.
Kimi-K2 solves: offers a native 256 K token context with flat pricing; processes massive input without chunking or the high long-context fees seen in Claude or GPT-4.
3. Cost-Sensitive Deployments
Task traits: large-scale runs or tight budgets (millions of tokens daily).
Kimi-K2 solves: delivers Claude/GPT-level reasoning at roughly 4–6× lower cost, making advanced reasoning affordable for startups and sustained workloads.
4. Domain Benchmark Parity
Task traits: complex reasoning, structured QA, or mathematical logic where closed models used to dominate.
Kimi-K2 solves: matches or exceeds GPT-5 and Claude 4.5 on AIME, HMMT, and GPQA Diamond, proving that open models can now perform at frontier levels in reasoning-heavy domains.
Kimi-K2-Thinking bridges the gap between closed proprietary systems and open innovation. It delivers near-Claude performance with 75–80% lower cost, supports 256K context windows, and sustains hundreds of reasoning or tool-use steps without drift. For developers needing deep reasoning, agentic workflows, or open-source deployment, Kimi-K2 offers a practical, scalable, and transparent solution that redefines cost-efficiency in advanced AI reasoning.
Frequently Asked Questions
What makes Kimi-K2-Thinking different from Claude Sonnet 4?
Kimi-K2 maintains coherent reasoning across 200–300 tool calls and costs up to 5× less, while Claude Sonnet 4’s price rises sharply with longer contexts and tool actions.
Is Kimi-K2-Thinking suitable for coding?
Yes. It can write and debug code effectively, but it performs best on reasoning-heavy or multi-step tool-driven projects rather than simple one-shot coding.
How large is Kimi-K2-Thinking’s context window?
It supports 256K tokens by default, enabling full codebase or document reasoning in one pass—without the premium long-context charges found in Claude or GPT models.
OneRouter provides a unified API that gives you access to hundreds of AI models through a single endpoint, while automatically handling fallbacks and selecting the most cost-effective options. Get started with just a few lines of code using your preferred SDK or framework.
More Articles

Track AI Model Token Usage
Usage Accounting in OneRouter
Track AI Model Token Usage
Usage Accounting in OneRouter

OneRouter Anthropic Claude API
OneRouter Now Supports Anthropic Claude API
OneRouter Anthropic Claude API
OneRouter Now Supports Anthropic Claude API

OneRouter OpenAI Responses API
OneRouter Now Supports the OpenAI Responses API
OneRouter OpenAI Responses API
OneRouter Now Supports the OpenAI Responses API
Scale without limits
Seamlessly integrate OneRouter with just a few lines of code and unlock unlimited AI power.

Scale without limits
Seamlessly integrate OneRouter with just a few lines of code and unlock unlimited AI power.
Scale without limits
Seamlessly integrate OneRouter with just a few lines of code and unlock unlimited AI power.