Manage the Complexity of Enterprise LLM Routing
OneRouter: The World's First Agentic LLM Router

Date
Dec 31, 2025
Author
Clarence Zhang
The proliferation of large language models presents enterprises with a critical challenge: optimizing for both cost efficiency, latency, and performance across heterogeneous model providers. This complexity is compounded by diverse LLM or AI agent workflows requiring different models, advanced capabilities like tool use, operational concerns such as cache management, and the increasing sophistication of agentic queries involving external tool calls.
OneRouter addresses this by providing a unified routing layer that operates beyond traditional gateway capabilities (authentication, quotas, rate limiting). It introduces the world's first intelligent agentic layer that analyzes query semantics, enterprise-level historical patterns, and real-time model dynamics to continuously recommend optimal model selections for cost, performance, region, and latency, etc.
The Complexity of Enterprise LLM Routing
Enterprise LLM deployment involves more than routing API calls. It requires managing gateway infrastructure, workflow dependencies, cost optimization strategies, and the growing complexity of tool-augmented agentic requests.
Traditional Gateway Requirements
LLM routing begins with foundational gateway capabilities: authentication, quotas, and rate limiting. OneRouter has invested significantly in optimizing these core functionalities, achieving 99.9% uptime and an initial 2000 RPM for enterprise clients.
Advanced Cost Management
Effective cost optimization extends beyond model pricing. LLM cache hits can reduce expenses by up to 90% per request, while factors like prompt caching policies, token pricing tiers, and regional availability further complicate routing decisions. Intelligent routing must synthesize these variables to achieve optimal cost-performance ratios.
Workflow-Level Dependencies
Modern enterprises deploy LLMs within complex workflows using platforms like n8n [1]. Each node in these workflows may involve multi-turn conversations with strict output format requirements. A suboptimal routing decision at one node can propagate errors downstream, cascading through dependent nodes and degrading overall workflow performance.
Increasing LLM Querying Complexity
Modern LLM queries extend far beyond simple text generation. Agentic requests now involve extensive tool calls such as web searches. OneRouter has built native support for some of these tools, including integrated search engine APIs [2], and we observed that there is are increasing number of LLMs with these external tools. Furthermore, enterprises exhibit vastly different querying patterns, with increasingly complex multi-step tool orchestration specific to their workflows.
OneRouter: An Agentic Routing Architecture
To address these challenges, we propose OneRouter, the first agentic LLM router that tackles enterprise complexity through an intelligent agentic layer.
The general architecture is illustrated below:
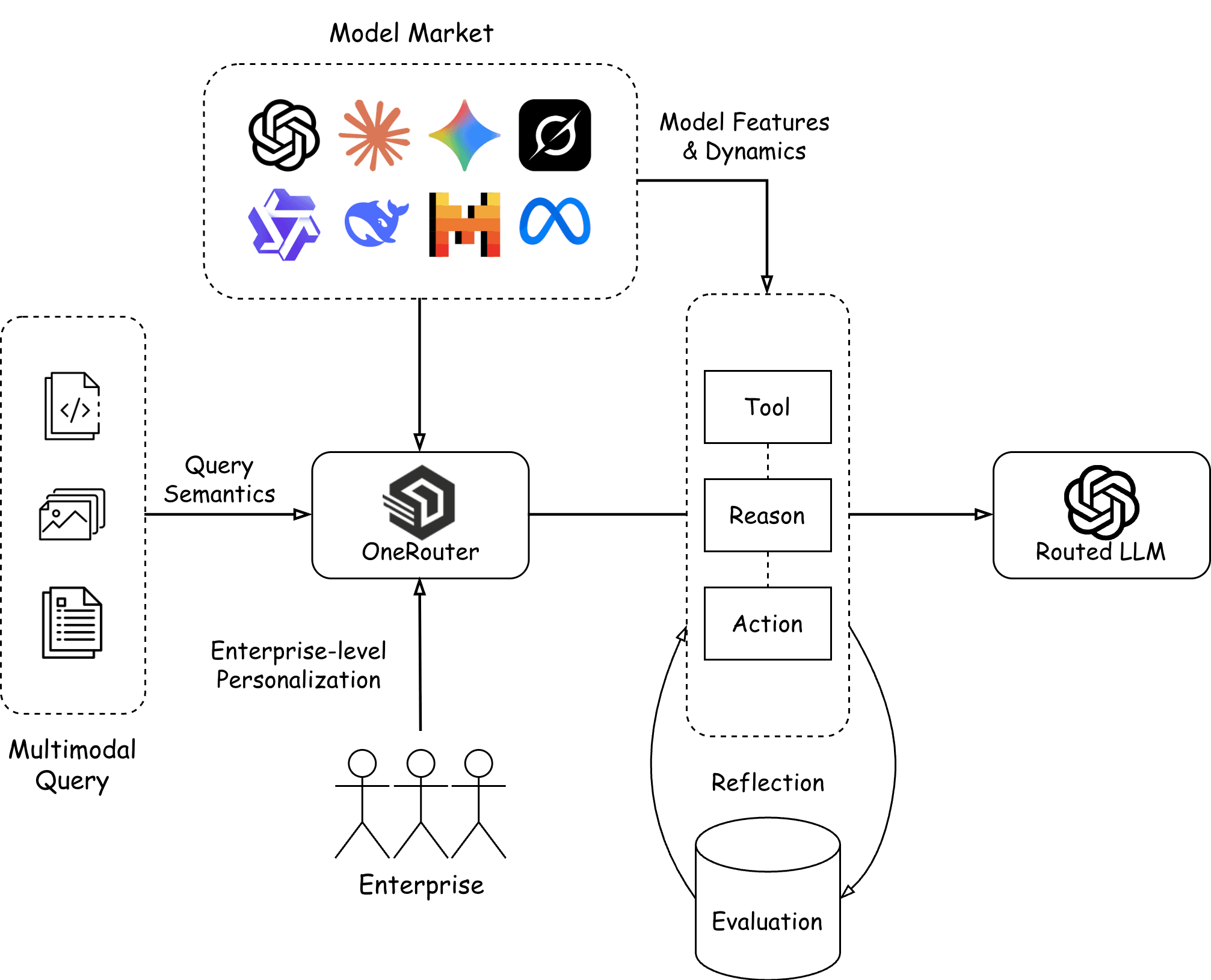
Query Analysis and Comprehension
The foundation of OneRouter lies in comprehending both the requirements and semantics of user queries. By analyzing query intent, complexity, context, and performance constraints (cost, latency), the router builds a comprehensive understanding of what each request demands.
Enterprise-Specific Learning and Personalization
Each enterprise exhibits vastly different usage patterns shaped by its unique agent and LLM workflows.
To accommodate this diversity, OneRouter incorporates a learning layer that analyzes and adapts to each enterprise's workflow patterns and historical usage (with explicit user permission). This learned context enriches each routing decision, accounting for workflow complexity, historical performance, and enterprise-specific requirements.
Model Market Dynamics
The LLM landscape evolves at a fast pace, with new models launching monthly or even weekly, alongside frequent pricing changes, capability updates, and regional availability shifts.
OneRouter tackles this challenge by continuously monitoring the model market and rapidly onboarding new providers. We've now integrated 40+ providers and developed specialized tools to capture market dynamics in real-time.
ReAct-Based Agentic Architecture
Traditional routing treats LLMs as deterministic services, making static decisions based on fixed rules or simple classifier models. However, modern LLM deployment requires reasoning-capable routers that can dynamically evaluate complex trade-offs. This demands a fundamentally different approach: routing as an intelligence control plane rather than simple traffic control.
Inspired by the ReAct framework [3], which combines reasoning and acting in language models, OneRouter implements this paradigm for intelligent routing decisions.
OneRouter adopts a ReAct-based architecture that "thinks first, acts, then decides." Before committing to a model selection, the router can:
Analyze query semantics and comprehension requirements
Retrieve relevant context from learned enterprise-level patterns for more fine-grained personalization recommendations
Query real-time model market dynamics (latency, pricing, regional availability) via specialized tools
This reasoning-driven approach enables the router to synthesize complex, multi-dimensional trade-offs that static classifiers cannot handle: balancing cost against latency for time-sensitive workflows, incorporating enterprise-specific historical patterns, and adapting to real-time market dynamics. By treating routing as a reasoning task rather than a classification problem, OneRouter transforms routing decisions from one-time lookups into a continuous learning process that builds collective intelligence from enterprise usage patterns.
Reflection and Self-Improvement
Drawing from the Reflexion framework [4], OneRouter routing decisions are automatically evaluated post-execution, capturing different metrics and performance outcomes. These evaluation results are persisted and made available to the agentic router for future decisions. This creates a continuous reflection loop where the router learns from its own successes and failures, refining its reasoning process over time and adapting to evolving enterprise requirements.
Experimental Evaluation
To validate OneRouter's effectiveness, we conducted experiments on 3,000 real-world queries spanning diverse enterprise use cases. Each query was routed by OneRouter to a recommended model, and the outputs were evaluated against baseline model selections across five dimensions: Factuality, Relevance, Fluency, Completeness, and Safety.
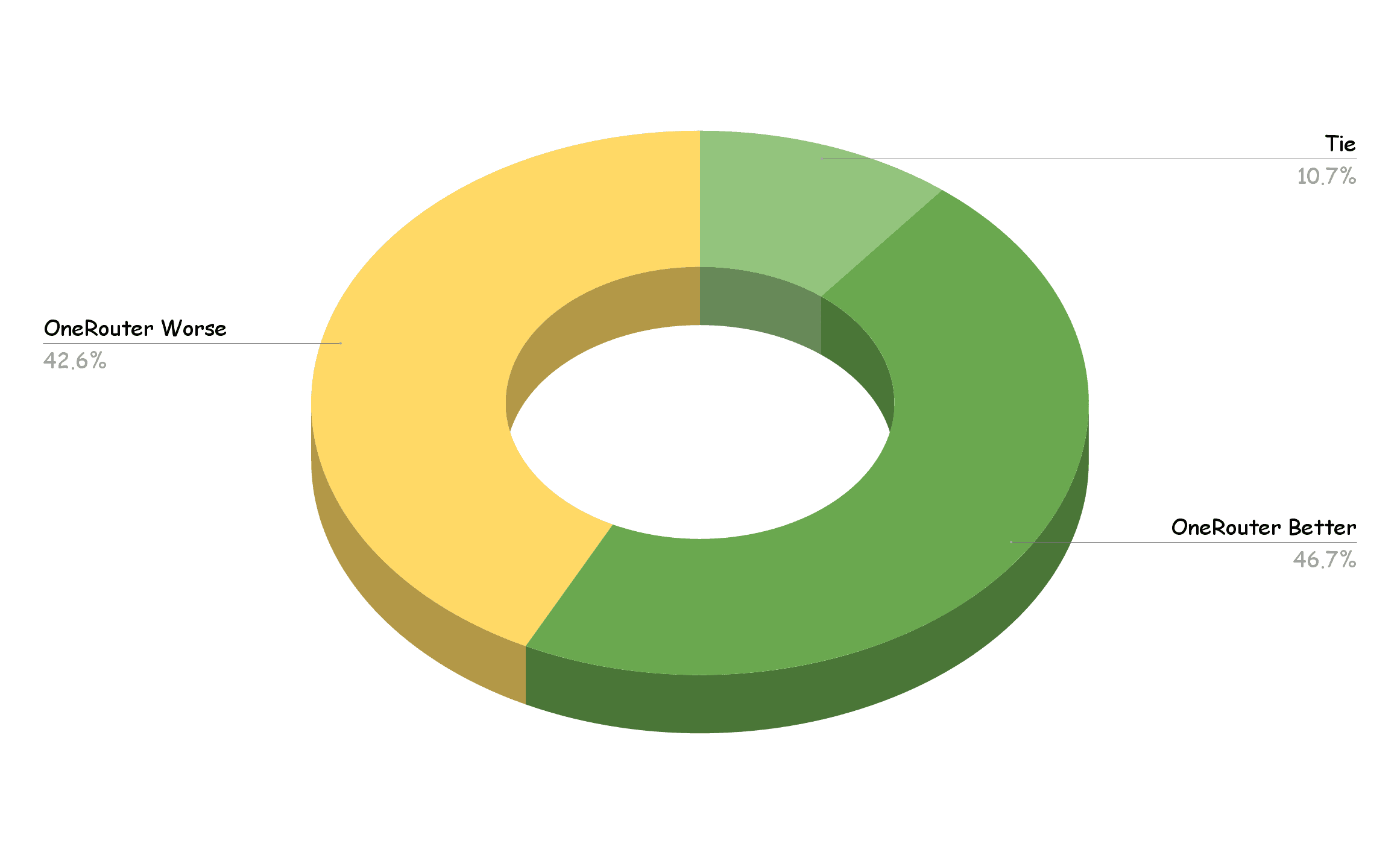
Results
The routing decisions demonstrated strong cost-performance optimization while maintaining quality:
10.7% of routed models achieved nearly identical performance to the baseline
46.7% of routed models delivered superior performance compared to the baseline
42.6% of routed models showed slightly reduced performance, with degradation less than 10%
Meanwhile, input token costs were reduced by approximately 50% and output token costs by approximately 65%, demonstrating substantial economic benefits alongside quality preservation.
Reference
[1] n8n - Workflow Automation Platform. https://n8n.io/
[2] OneRouter Search Engine API. https://docs.onerouter.pro/api-reference/search-engine-api
[3] ReAct: Synergizing Reasoning and Acting in Language Models. https://arxiv.org/abs/2210.03629
[4] Reflexion: Language Agents with Verbal Reinforcement Learning. https://arxiv.org/abs/2303.11366
The proliferation of large language models presents enterprises with a critical challenge: optimizing for both cost efficiency, latency, and performance across heterogeneous model providers. This complexity is compounded by diverse LLM or AI agent workflows requiring different models, advanced capabilities like tool use, operational concerns such as cache management, and the increasing sophistication of agentic queries involving external tool calls.
OneRouter addresses this by providing a unified routing layer that operates beyond traditional gateway capabilities (authentication, quotas, rate limiting). It introduces the world's first intelligent agentic layer that analyzes query semantics, enterprise-level historical patterns, and real-time model dynamics to continuously recommend optimal model selections for cost, performance, region, and latency, etc.
The Complexity of Enterprise LLM Routing
Enterprise LLM deployment involves more than routing API calls. It requires managing gateway infrastructure, workflow dependencies, cost optimization strategies, and the growing complexity of tool-augmented agentic requests.
Traditional Gateway Requirements
LLM routing begins with foundational gateway capabilities: authentication, quotas, and rate limiting. OneRouter has invested significantly in optimizing these core functionalities, achieving 99.9% uptime and an initial 2000 RPM for enterprise clients.
Advanced Cost Management
Effective cost optimization extends beyond model pricing. LLM cache hits can reduce expenses by up to 90% per request, while factors like prompt caching policies, token pricing tiers, and regional availability further complicate routing decisions. Intelligent routing must synthesize these variables to achieve optimal cost-performance ratios.
Workflow-Level Dependencies
Modern enterprises deploy LLMs within complex workflows using platforms like n8n [1]. Each node in these workflows may involve multi-turn conversations with strict output format requirements. A suboptimal routing decision at one node can propagate errors downstream, cascading through dependent nodes and degrading overall workflow performance.
Increasing LLM Querying Complexity
Modern LLM queries extend far beyond simple text generation. Agentic requests now involve extensive tool calls such as web searches. OneRouter has built native support for some of these tools, including integrated search engine APIs [2], and we observed that there is are increasing number of LLMs with these external tools. Furthermore, enterprises exhibit vastly different querying patterns, with increasingly complex multi-step tool orchestration specific to their workflows.
OneRouter: An Agentic Routing Architecture
To address these challenges, we propose OneRouter, the first agentic LLM router that tackles enterprise complexity through an intelligent agentic layer.
The general architecture is illustrated below:
Query Analysis and Comprehension
The foundation of OneRouter lies in comprehending both the requirements and semantics of user queries. By analyzing query intent, complexity, context, and performance constraints (cost, latency), the router builds a comprehensive understanding of what each request demands.
Enterprise-Specific Learning and Personalization
Each enterprise exhibits vastly different usage patterns shaped by its unique agent and LLM workflows.
To accommodate this diversity, OneRouter incorporates a learning layer that analyzes and adapts to each enterprise's workflow patterns and historical usage (with explicit user permission). This learned context enriches each routing decision, accounting for workflow complexity, historical performance, and enterprise-specific requirements.
Model Market Dynamics
The LLM landscape evolves at a fast pace, with new models launching monthly or even weekly, alongside frequent pricing changes, capability updates, and regional availability shifts.
OneRouter tackles this challenge by continuously monitoring the model market and rapidly onboarding new providers. We've now integrated 40+ providers and developed specialized tools to capture market dynamics in real-time.
ReAct-Based Agentic Architecture
Traditional routing treats LLMs as deterministic services, making static decisions based on fixed rules or simple classifier models. However, modern LLM deployment requires reasoning-capable routers that can dynamically evaluate complex trade-offs. This demands a fundamentally different approach: routing as an intelligence control plane rather than simple traffic control.
Inspired by the ReAct framework [3], which combines reasoning and acting in language models, OneRouter implements this paradigm for intelligent routing decisions.
OneRouter adopts a ReAct-based architecture that "thinks first, acts, then decides." Before committing to a model selection, the router can:
Analyze query semantics and comprehension requirements
Retrieve relevant context from learned enterprise-level patterns for more fine-grained personalization recommendations
Query real-time model market dynamics (latency, pricing, regional availability) via specialized tools
This reasoning-driven approach enables the router to synthesize complex, multi-dimensional trade-offs that static classifiers cannot handle: balancing cost against latency for time-sensitive workflows, incorporating enterprise-specific historical patterns, and adapting to real-time market dynamics. By treating routing as a reasoning task rather than a classification problem, OneRouter transforms routing decisions from one-time lookups into a continuous learning process that builds collective intelligence from enterprise usage patterns.
Reflection and Self-Improvement
Drawing from the Reflexion framework [4], OneRouter routing decisions are automatically evaluated post-execution, capturing different metrics and performance outcomes. These evaluation results are persisted and made available to the agentic router for future decisions. This creates a continuous reflection loop where the router learns from its own successes and failures, refining its reasoning process over time and adapting to evolving enterprise requirements.
Experimental Evaluation
To validate OneRouter's effectiveness, we conducted experiments on 3,000 real-world queries spanning diverse enterprise use cases. Each query was routed by OneRouter to a recommended model, and the outputs were evaluated against baseline model selections across five dimensions: Factuality, Relevance, Fluency, Completeness, and Safety.
Results
The routing decisions demonstrated strong cost-performance optimization while maintaining quality:
10.7% of routed models achieved nearly identical performance to the baseline
46.7% of routed models delivered superior performance compared to the baseline
42.6% of routed models showed slightly reduced performance, with degradation less than 10%
Meanwhile, input token costs were reduced by approximately 50% and output token costs by approximately 65%, demonstrating substantial economic benefits alongside quality preservation.
Reference
[1] n8n - Workflow Automation Platform. https://n8n.io/
[2] OneRouter Search Engine API. https://docs.onerouter.pro/api-reference/search-engine-api
[3] ReAct: Synergizing Reasoning and Acting in Language Models. https://arxiv.org/abs/2210.03629
[4] Reflexion: Language Agents with Verbal Reinforcement Learning. https://arxiv.org/abs/2303.11366
More Articles

Track AI Model Token Usage
Usage Accounting in OneRouter
Track AI Model Token Usage
Usage Accounting in OneRouter

OneRouter Anthropic Claude API
OneRouter Now Supports Anthropic Claude API
OneRouter Anthropic Claude API
OneRouter Now Supports Anthropic Claude API

OneRouter OpenAI Responses API
OneRouter Now Supports the OpenAI Responses API
OneRouter OpenAI Responses API
OneRouter Now Supports the OpenAI Responses API
Scale without limits
Seamlessly integrate OneRouter with just a few lines of code and unlock unlimited AI power.

Scale without limits
Seamlessly integrate OneRouter with just a few lines of code and unlock unlimited AI power.
Scale without limits
Seamlessly integrate OneRouter with just a few lines of code and unlock unlimited AI power.