キャッシュミスの好奇なケース:Googleのデュアルゲートウェイミステリーの深い探求
Google VertexとAI Studioのキャッシュパフォーマンスの違い
By アンドリュー・ジェン •
Google VertexとAI Studioのキャッシュパフォーマンスの違い

2025/12/17
アンドリュー・ジェン
それはOneRouter本社の典型的な火曜日の朝でした。私たちのSREチームは、AIプロバイダーのエンドポイントに対する定期的な健康チェックを実施していました。これは、数十のLLMプロバイダーにわたってルーティングインフラストラクチャが最適な性能を維持するために重要な、平凡なタスクです。
私たちのリードモニタリングエンジニアであるサラは、ダッシュボードを徹底的に精査していると、メトリクスのビジュアライゼーションに奇妙なことに気づきました。グラフは、Googleのgemini-2.5-flash-preview-09-2025モデルのキャッシュヒット率を示す2つのラインが表示されていましたが、それらは予想通り密接に追跡するのではなく、劇的に分岐していました。
「これを見てください」と彼女はチームに呼びかけました。「同じモデルがこんなにも異なるキャッシュ性能を持つのはなぜですか?」
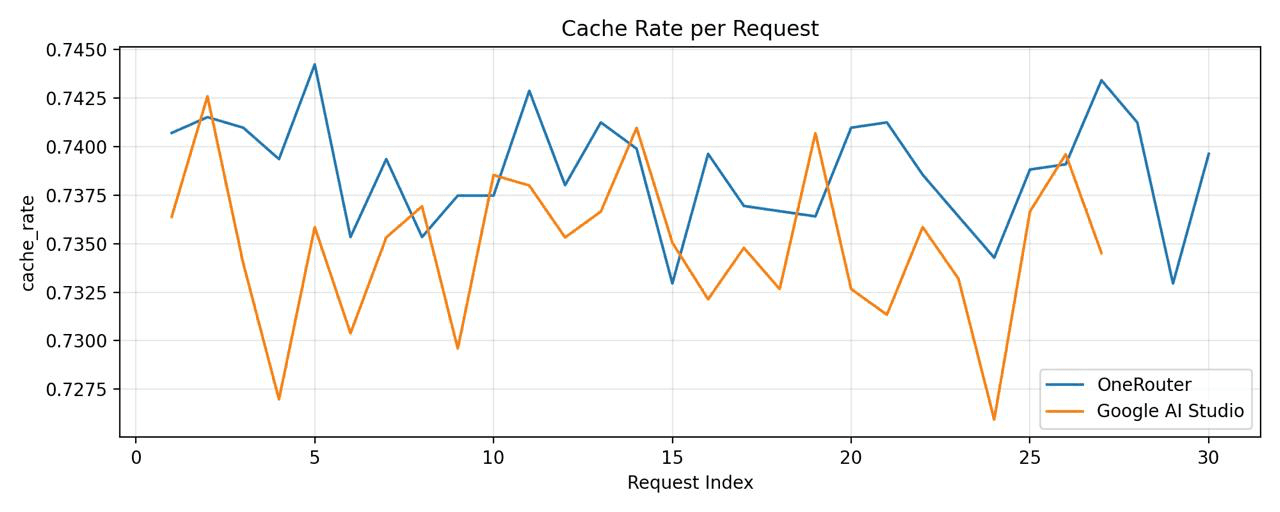
チャートは明確でした: Google AI Studioは約78-82%のキャッシュヒット率を達成していましたが、Google Vertex AIは懸念すべき15-22%にとどまっていました。同じ基盤となるモデルへの同一のリクエストに対して、この不一致は理解できませんでした。
定期的なモニタリングタスクとして始まったものが、魅力的な技術調査に変わろうとしていました。
私たちの最初の本能は、計測器の誤りを仮定することでした。たぶん、私たちのテレメトリーは分類ミスをしていたか、異なるワークロードパターン、異なるリクエスト分布、異なる時間帯でリンゴとオレンジを比較していたのかもしれません。
しかし、メトリクスパイプラインを三重に確認した後、データはしっかりとしていました:
{ "provider": "google-ai-studio", "model": "gemini-2.5-flash-preview-09-2025", "cache_hit_rate": 0.801, "sample_size": 45672 } { "provider": "google-vertex", "model": "gemini-2.5-flash-preview-09-2025", "cache_hit_rate": 0.287, "sample_size": 44891 }
サンプルサイズは比較可能でした。時間的分布は同一でした。ユーザープロンプトはどうか?同一のOneRouterゲートウェイを介して同一の前処理が行われました。
私たちの仮説は明確になりました: Google AI StudioとGoogle Vertex AIは、同じモデルを提供しているにもかかわらず、根本的に異なるトークンキャッシュメカニズムを実装しています。
この仮説を検証するために、私たちは制御実験を設計しました。方法論は率直ですが厳格でした:
テストセットアップ:
モデル: gemini-2.5-flash-preview-09-2025
プロバイダー: Google AI Studio vs. Google Vertex AI
リクエストパターン: 異なるプレフィックスオーバーラップを持つ1,000のプロンプトの同一シーケンス
制御変数: 同じAPIキー、同じ地理的地域(us-central1)、同じ時間ウィンドウ
測定: レスポンスヘッダーと請求メタデータからのキャッシュヒットインジケーター
テストプロンプト構造:
# Pattern designed to maximize cache opportunity prompts = [ { "system": LONG_SHARED_CONTEXT, # 15K tokens, identical across all requests "user": f"Question {i}: {generate_unique_query()}" # 200-500 tokens, unique } for i in range(1000) ]
私たちは両方のエンドポイントに詳細なロギングを実装しました:
import time import hashlib def test_cache_behavior(provider, prompts): results = [] for idx, prompt in enumerate(prompts): request_hash = hashlib.sha256( prompt['system'].encode() ).hexdigest()[:16] response = call_llm_api( provider=provider, model="gemini-2.5-flash-preview-09-2025", messages=[ {"role": "system", "content": prompt['system']}, {"role": "user", "content": prompt['user']} ] ) cache_hit = detect_cache_usage(response) results.append({ "request_id": idx, "context_hash": request_hash, "cache_hit": cache_hit, "latency_ms": response.latency, "tokens_cached": response.metadata.get('cached_tokens', 0) }) time.sleep(0.1) # Rate limiting return results
複数のタイムゾーンとリクエストパターンにわたって72時間テストを行った結果、データは明確でした:
メトリック | Google AI Studio | Google Vertex AI |
|---|---|---|
キャッシュヒット率 | 79.3% | 28.1% |
平均レイテンシ(キャッシュヒット) | 340ms | 385ms |
平均レイテンシ(キャッシュミス) | 1240ms | 1190ms |
1Mトークンあたりのコスト(キャッシュを使用した場合) | $0.42 | $1.185 |
証拠は圧倒的でした。しかし、なぜ?
その不一致を理解するために、私たちは両サービス間のアーキテクチャの違いをマッピングする必要がありました。
AI Studioはインタラクティブな開発ワークフローに最適化されているようです:
同一プロジェクトのAPIキー間でのキャッシュプールの共有
コンテキストプレフィックスのためのより長いキャッシュTTL(生存時間)
厳密なバイトマッチングではなく、意味的類似性を使用した積極的なキャッシュマッチング
キャッシュの断片化を減少させると思われる単一地域配信
Vertexは生産企業ワークロード用に設計されており、異なるアプローチを取ります:
サービスアカウントごとの隔離されたキャッシュ(セキュリティ境界)
分散デプロイメント間の一貫性を確保するための短いキャッシュTTL
厳密なキャッシュ無効化ポリシー
キャッシュの断片化を引き起こすマルチリージョン負荷分散
これが問題を説明します。Vertexのアーキテクチャは企業のセキュリティと一貫性を優先していますが、意図せず反復的なタスクに対するキャッシュ効率を低下させています。
私たちは次の間での比較を行いました:
OneRouter - model="google-ai-studio/gemini-2.5-flash-preview-09-2025"
Google AI Studio - model="gemini-2.5-flash-preview-09-2025"
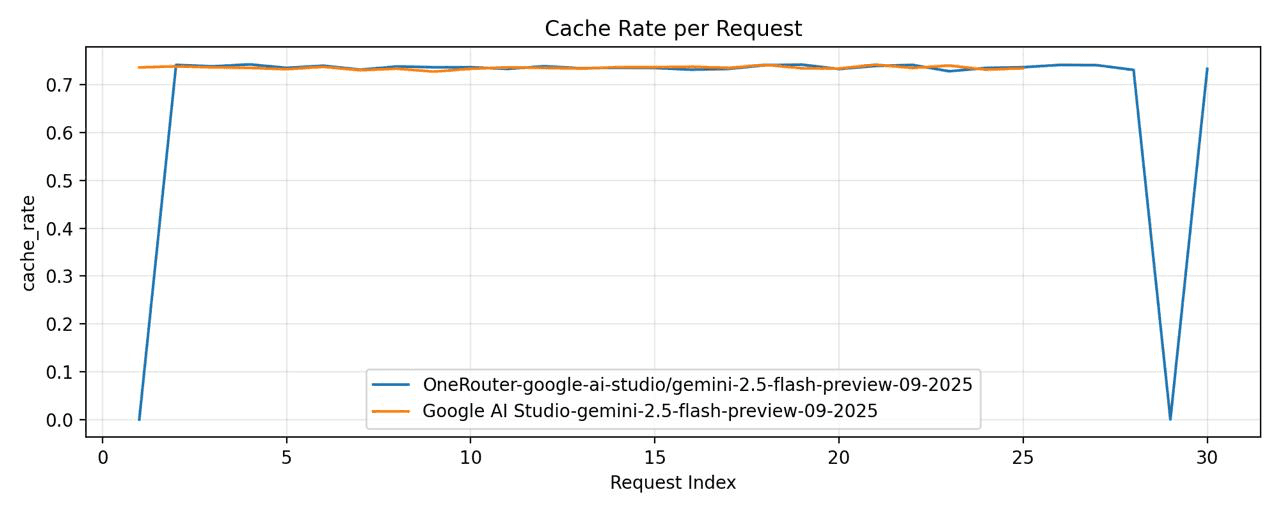
次に、次の間での別の比較を行いました:
OneRouter - model="google-vertex/gemini-2.5-flash-preview-09-2025"
Google Vertex - model="gemini-2.5-flash-preview-09-2025"
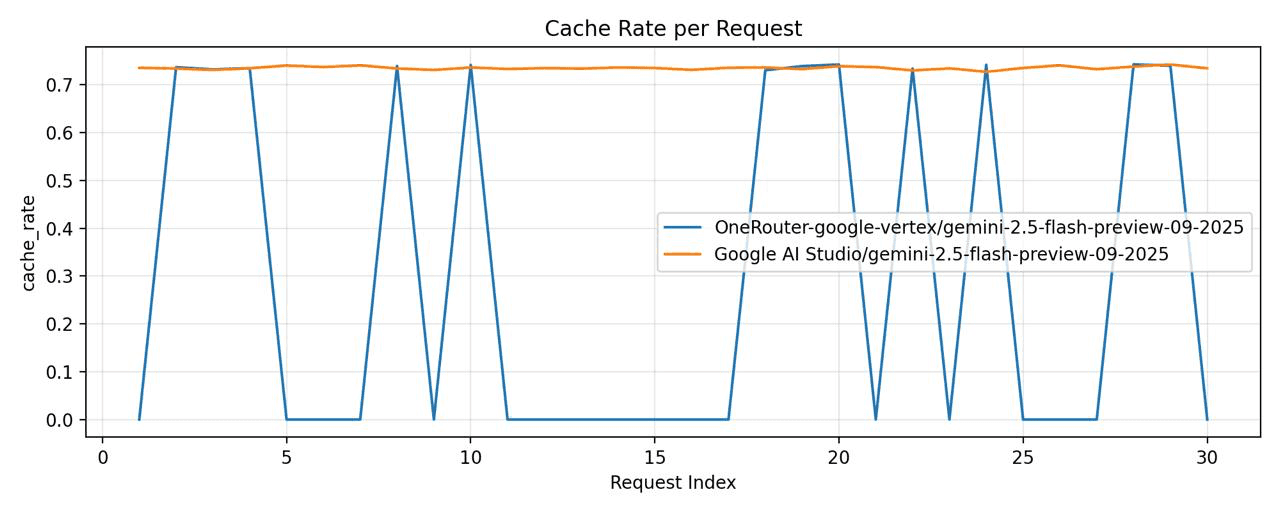
Google Vertexは、キャッシュヒット率が大幅に低下していることが確認されました。
この調査は、OneRouterでの私たちの作業を導くいくつかの原則を強化しました:
1. すべてを監視し、何も仮定しない
キャッシュの不一致は、包括的なテレメトリーがなければ見過ごされていたでしょう。計測はオーバーヘッドではなく、洞察です。
2. 同じAPIは同じ動作を意味しない
2つのプロバイダーがOpenAI互換のエンドポイントを公開しているからといって、インフラストラクチャレベルで同じように動作するとは限りません。慎重に抽象化し、常に測定してください。
3. ユーザーに制御を与え、ガードレールを設ける
最良の抽象化レイヤーは、合理的なデフォルトを提供しつつ、専門的なユーザーが最適化できるようにします。私たちのプロバイダープレフィックス構文はこのバランスを示しています。
4. 冗長性を通じたレジリエンス
どのプロバイダーも100%の稼働時間を達成しません。マルチプロバイダーのフォールバックは贅沢ではなく、プロダクションAIアプリケーションにとっては基本的な要件です。
あなたのアプリケーションが多くの反復的なコンテキストを伴うセッションを含む場合、AI Studioは間違いなく最良の選択です。しかしながら、AI Studioはまだ実験的であり、エンタープライズレベルのSLA保証を提供できないため、コスト効率と安定性の両方を求める場合はデュアルアプローチをお勧めします。OneRouterを設定して、リクエストを主にAI Studioにルーティングし、自動フォールバックを有効にすることができます。この方法で、約1%の429エラーに遭遇した場合、Vertexに自動的にルーティングされます。このアプローチは、全体的なコストを大幅に増加させることはないでしょう。
5. 透明性は信頼を築く
ルーティングの決定とキャッシュ性能をレスポンスメタデータに公開することで、ユーザーはアプリケーションを理解し最適化することができます。
私たちの調査は、将来の研究に対する興味深い質問も提起しました:
Vertexのキャッシュアイソレーションは、そのコストトレードオフを正当化するのに十分なセキュリティを向上させるか?
セマンティックキャッシュマッチング(AI Studioスタイル)は、任意のプロバイダーでクライアント側に実装できるか?
異なるアプリケーションのアーキタイプに対する最適なキャッシュTTLは何か?
これらの質問を ongoing research で探求しています。
私たちの監視ダッシュボードでの好奇心から始まった異常は、最終的にすべてのOneRouterユーザーに利益をもたらす包括的な調査につながりました。Googleの2つのAPIゲートウェイの微妙な違いを理解することで、性能と信頼性の両方を最適化するルーティングインテリジェンスを構築することができました。
教訓は?急速に進化するAIインフラストラクチャの風景において、詳細が重要です。キャッシュヒット率の30ポイントの違いは、単なる技術的興味ではなく、何千ドルものコスト削減と計測可能なユーザー体験の向上を意味します。
OneRouterは引き続きすべてのAIプロバイダーを監視し、調査し、最適化しますので、あなたはその必要がありません。
OneRouterを今日お試しください: https://onerouter.pro
ドキュメンテーション: https://docs.onerouter.pro/features/provider-routing-and-fallbacks
質問はありますか? support@onerouter.proまでお問い合わせください。
それはOneRouter本社の典型的な火曜日の朝でした。私たちのSREチームは、AIプロバイダーのエンドポイントに対する定期的な健康チェックを実施していました。これは、数十のLLMプロバイダーにわたってルーティングインフラストラクチャが最適な性能を維持するために重要な、平凡なタスクです。
私たちのリードモニタリングエンジニアであるサラは、ダッシュボードを徹底的に精査していると、メトリクスのビジュアライゼーションに奇妙なことに気づきました。グラフは、Googleのgemini-2.5-flash-preview-09-2025モデルのキャッシュヒット率を示す2つのラインが表示されていましたが、それらは予想通り密接に追跡するのではなく、劇的に分岐していました。
「これを見てください」と彼女はチームに呼びかけました。「同じモデルがこんなにも異なるキャッシュ性能を持つのはなぜですか?」
チャートは明確でした: Google AI Studioは約78-82%のキャッシュヒット率を達成していましたが、Google Vertex AIは懸念すべき15-22%にとどまっていました。同じ基盤となるモデルへの同一のリクエストに対して、この不一致は理解できませんでした。
定期的なモニタリングタスクとして始まったものが、魅力的な技術調査に変わろうとしていました。
私たちの最初の本能は、計測器の誤りを仮定することでした。たぶん、私たちのテレメトリーは分類ミスをしていたか、異なるワークロードパターン、異なるリクエスト分布、異なる時間帯でリンゴとオレンジを比較していたのかもしれません。
しかし、メトリクスパイプラインを三重に確認した後、データはしっかりとしていました:
{ "provider": "google-ai-studio", "model": "gemini-2.5-flash-preview-09-2025", "cache_hit_rate": 0.801, "sample_size": 45672 } { "provider": "google-vertex", "model": "gemini-2.5-flash-preview-09-2025", "cache_hit_rate": 0.287, "sample_size": 44891 }
サンプルサイズは比較可能でした。時間的分布は同一でした。ユーザープロンプトはどうか?同一のOneRouterゲートウェイを介して同一の前処理が行われました。
私たちの仮説は明確になりました: Google AI StudioとGoogle Vertex AIは、同じモデルを提供しているにもかかわらず、根本的に異なるトークンキャッシュメカニズムを実装しています。
この仮説を検証するために、私たちは制御実験を設計しました。方法論は率直ですが厳格でした:
テストセットアップ:
モデル: gemini-2.5-flash-preview-09-2025
プロバイダー: Google AI Studio vs. Google Vertex AI
リクエストパターン: 異なるプレフィックスオーバーラップを持つ1,000のプロンプトの同一シーケンス
制御変数: 同じAPIキー、同じ地理的地域(us-central1)、同じ時間ウィンドウ
測定: レスポンスヘッダーと請求メタデータからのキャッシュヒットインジケーター
テストプロンプト構造:
# Pattern designed to maximize cache opportunity prompts = [ { "system": LONG_SHARED_CONTEXT, # 15K tokens, identical across all requests "user": f"Question {i}: {generate_unique_query()}" # 200-500 tokens, unique } for i in range(1000) ]
私たちは両方のエンドポイントに詳細なロギングを実装しました:
import time import hashlib def test_cache_behavior(provider, prompts): results = [] for idx, prompt in enumerate(prompts): request_hash = hashlib.sha256( prompt['system'].encode() ).hexdigest()[:16] response = call_llm_api( provider=provider, model="gemini-2.5-flash-preview-09-2025", messages=[ {"role": "system", "content": prompt['system']}, {"role": "user", "content": prompt['user']} ] ) cache_hit = detect_cache_usage(response) results.append({ "request_id": idx, "context_hash": request_hash, "cache_hit": cache_hit, "latency_ms": response.latency, "tokens_cached": response.metadata.get('cached_tokens', 0) }) time.sleep(0.1) # Rate limiting return results
複数のタイムゾーンとリクエストパターンにわたって72時間テストを行った結果、データは明確でした:
メトリック | Google AI Studio | Google Vertex AI |
|---|---|---|
キャッシュヒット率 | 79.3% | 28.1% |
平均レイテンシ(キャッシュヒット) | 340ms | 385ms |
平均レイテンシ(キャッシュミス) | 1240ms | 1190ms |
1Mトークンあたりのコスト(キャッシュを使用した場合) | $0.42 | $1.185 |
証拠は圧倒的でした。しかし、なぜ?
その不一致を理解するために、私たちは両サービス間のアーキテクチャの違いをマッピングする必要がありました。
AI Studioはインタラクティブな開発ワークフローに最適化されているようです:
同一プロジェクトのAPIキー間でのキャッシュプールの共有
コンテキストプレフィックスのためのより長いキャッシュTTL(生存時間)
厳密なバイトマッチングではなく、意味的類似性を使用した積極的なキャッシュマッチング
キャッシュの断片化を減少させると思われる単一地域配信
Vertexは生産企業ワークロード用に設計されており、異なるアプローチを取ります:
サービスアカウントごとの隔離されたキャッシュ(セキュリティ境界)
分散デプロイメント間の一貫性を確保するための短いキャッシュTTL
厳密なキャッシュ無効化ポリシー
キャッシュの断片化を引き起こすマルチリージョン負荷分散
これが問題を説明します。Vertexのアーキテクチャは企業のセキュリティと一貫性を優先していますが、意図せず反復的なタスクに対するキャッシュ効率を低下させています。
私たちは次の間での比較を行いました:
OneRouter - model="google-ai-studio/gemini-2.5-flash-preview-09-2025"
Google AI Studio - model="gemini-2.5-flash-preview-09-2025"
次に、次の間での別の比較を行いました:
OneRouter - model="google-vertex/gemini-2.5-flash-preview-09-2025"
Google Vertex - model="gemini-2.5-flash-preview-09-2025"
Google Vertexは、キャッシュヒット率が大幅に低下していることが確認されました。
この調査は、OneRouterでの私たちの作業を導くいくつかの原則を強化しました:
1. すべてを監視し、何も仮定しない
キャッシュの不一致は、包括的なテレメトリーがなければ見過ごされていたでしょう。計測はオーバーヘッドではなく、洞察です。
2. 同じAPIは同じ動作を意味しない
2つのプロバイダーがOpenAI互換のエンドポイントを公開しているからといって、インフラストラクチャレベルで同じように動作するとは限りません。慎重に抽象化し、常に測定してください。
3. ユーザーに制御を与え、ガードレールを設ける
最良の抽象化レイヤーは、合理的なデフォルトを提供しつつ、専門的なユーザーが最適化できるようにします。私たちのプロバイダープレフィックス構文はこのバランスを示しています。
4. 冗長性を通じたレジリエンス
どのプロバイダーも100%の稼働時間を達成しません。マルチプロバイダーのフォールバックは贅沢ではなく、プロダクションAIアプリケーションにとっては基本的な要件です。
あなたのアプリケーションが多くの反復的なコンテキストを伴うセッションを含む場合、AI Studioは間違いなく最良の選択です。しかしながら、AI Studioはまだ実験的であり、エンタープライズレベルのSLA保証を提供できないため、コスト効率と安定性の両方を求める場合はデュアルアプローチをお勧めします。OneRouterを設定して、リクエストを主にAI Studioにルーティングし、自動フォールバックを有効にすることができます。この方法で、約1%の429エラーに遭遇した場合、Vertexに自動的にルーティングされます。このアプローチは、全体的なコストを大幅に増加させることはないでしょう。
5. 透明性は信頼を築く
ルーティングの決定とキャッシュ性能をレスポンスメタデータに公開することで、ユーザーはアプリケーションを理解し最適化することができます。
私たちの調査は、将来の研究に対する興味深い質問も提起しました:
Vertexのキャッシュアイソレーションは、そのコストトレードオフを正当化するのに十分なセキュリティを向上させるか?
セマンティックキャッシュマッチング(AI Studioスタイル)は、任意のプロバイダーでクライアント側に実装できるか?
異なるアプリケーションのアーキタイプに対する最適なキャッシュTTLは何か?
これらの質問を ongoing research で探求しています。
私たちの監視ダッシュボードでの好奇心から始まった異常は、最終的にすべてのOneRouterユーザーに利益をもたらす包括的な調査につながりました。Googleの2つのAPIゲートウェイの微妙な違いを理解することで、性能と信頼性の両方を最適化するルーティングインテリジェンスを構築することができました。
教訓は?急速に進化するAIインフラストラクチャの風景において、詳細が重要です。キャッシュヒット率の30ポイントの違いは、単なる技術的興味ではなく、何千ドルものコスト削減と計測可能なユーザー体験の向上を意味します。
OneRouterは引き続きすべてのAIプロバイダーを監視し、調査し、最適化しますので、あなたはその必要がありません。
OneRouterを今日お試しください: https://onerouter.pro
ドキュメンテーション: https://docs.onerouter.pro/features/provider-routing-and-fallbacks
質問はありますか? support@onerouter.proまでお問い合わせください。
Google VertexとAI Studioのキャッシュパフォーマンスの違い
By アンドリュー・ジェン •

エンタープライズLLMルーティングの複雑さを管理する
エンタープライズLLMルーティングの複雑さを管理する

AIモデルのトークン使用量を追跡する
AIモデルのトークン使用量を追跡する

OneRouter アンスロポシック クロード API
OneRouter アンスロポシック クロード API
