LLMルーターとは何ですか?
AIルーティング技術
By アンドリュー・ジェン •
AIルーティング技術

2025/11/25
アンドリュー・ジェン
大規模言語モデル(LLMs)は、現代のAIアプリケーションの基盤となり、チャットボットやバーチャルアシスタントから研究ツールや企業ソリューションまで、あらゆるものを支えています。しかし、すべてのLLMが同じではなく、それぞれ独自の強み、限界、およびコスト要因があります。あるものは推論に優れ、他のものは創造的な執筆、コーディング、または構造化クエリの処理に秀でています。ここで、LLMルーターが登場します。
LLMルーターは、知的な交通管理者のような役割を果たし、ユーザーのプロンプトをタスクに基づいて最も適切なモデルに自動的に誘導します。単一のモデルに頼る代わりに、企業や開発者はリアルタイムで適切なLLMにクエリをルーティングすることで、パフォーマンス、精度、およびコストを最適化できます。AIの採用が進むにつれ、LLMルーティングは、スケーラブルで信頼性が高く効率的なAIシステムを構築するための重要なレイヤーになりつつあります。
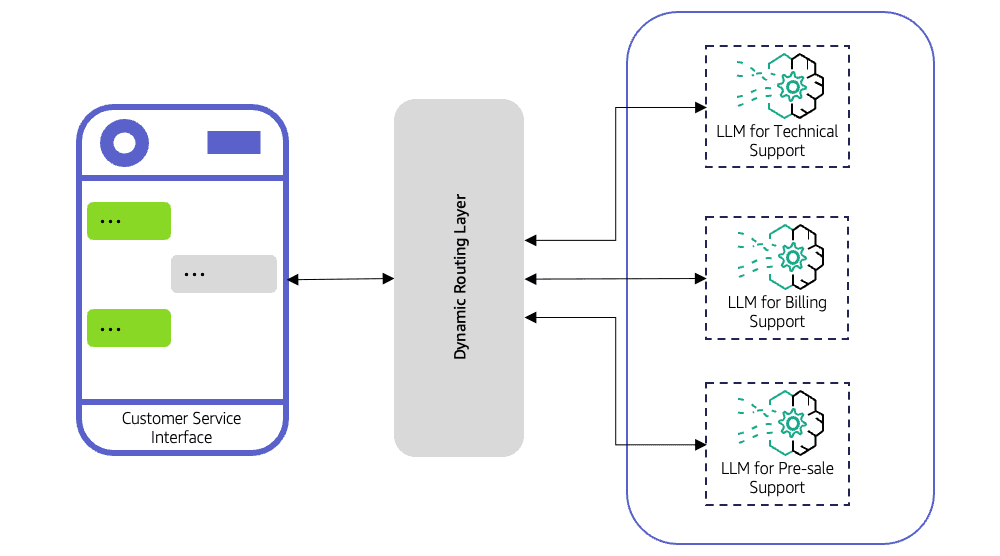
LLMルーターは、どの大規模言語モデルが各リクエストを処理すべきかを決定します。すべてのクエリを単一のモデルに送信するのではなく、入力を評価し、ルーティングロジックを適用し、最も適切なモデルに転送します。
ルーターは、コーディング関連のクエリをプログラミングに特化したモデルに誘導するような単純なルールに従ったり、分類器、埋め込み、または軽量予測モデルなどの高度な戦略を使用して、どのLLMが最良の応答を提供するかを判断することができます。
入力:ルーターは、ユーザーのクエリを受け取ります。
分析:クエリを検査し、メタデータ、タグ、タイプ、複雑さ、さらには意図や感情を確認します。これにより、リクエストの正確な要件を理解します。
モデル選択:ルーターは、ドメイン専門知識、精度、レイテンシ、コストなどの要因に基づいて最も適切なLLMを選択します。
フォールバックメカニズム:選択されたモデルが失敗、タイムアウト、または低信頼で回答を生成した場合、ルーターは信頼性を維持するために自動的にリクエストをバックアップモデルにリダイレクトします。
このアプローチは「一律に受け入れる」問題を排除します。軽量モデルはルーチンなクエリを効率的に処理し、複雑または推論に重いタスクはより能力の高いLLMに送られます。
実際には、ルーターはアプリケーションと複数のLLMの間に位置し、パフォーマンスを最適化し、コストを削減し、単一のプロバイダーへの依存を最小限に抑えます。このセットアップにより、すべてのリクエストが適切なモデルに届きながら、AIシステムが信頼性が高く柔軟であることが保証されます。
企業はますます、チャットボットやバーチャルアシスタントからコンテンツ作成やデータ分析に至るまでのタスクに対して、大規模言語モデルに頼っています。
ただし、すべてのタスクに単一のLLMを使用することは、課題を引き起こします。一部のモデルは迅速に応答しますが、深みが欠けている一方、他のモデルは高いレイテンシとコストで正確な結果を提供します。これらの違いを管理する方法がなければ、チームは常にパフォーマンス、精度、予算のトレードオフを強いられます。
LLMルーターは、タスクに最も適したモデルにリクエストを知的に誘導することでこれを解決します。
カスタマーサポートシステムは、2種類のクエリを受け取ります。
「あなたの営業時間は?」のような単純なリクエストは、高度なモデルを必要としない一方で、製品トラブルシューティングに関する複雑な技術的質問は必要です。LLMルーターなしでは、すべてのクエリが高出力の高価なモデルに送信される可能性があります。これによりコストが増加し、応答時間が遅くなります。ルーターを使用すると、単純なクエリは迅速な軽量モデルに送信され、複雑なクエリはより能力の高いLLMにルーティングされ、速度、コスト、精度が最適化されます。
最適化されたパフォーマンス:クエリの複雑さに合ったモデルをマッチングします。
コスト効率:ルーチンなタスクに高価なモデルを過剰使用するのを避けます。
信頼性:フォールバックメカニズムは、モデルが失敗した場合でも一貫した応答を保証します。
柔軟性:ベンダーロックインを避けるために、異なるプロバイダーからのモデルを組み合わせます。
スケーラビリティ:増加するクエリボリュームと負荷分散を効率的に管理します。
知的にクエリをルーティングすることで、企業は迅速で、より正確で、コスト効率の良いAIサービスを提供します。LLMルーターは、AIの展開を一律のアプローチから柔軟で信頼性が高く効率的なシステムに変革し、現代のAIインフラにとって欠かせない存在にしています。
LLMルーターは単なる交通指導者以上のものであり、AIシステムをよりスマートで迅速かつ信頼性のあるものにするためのいくつかのコア機能を提供します。これらの機能を理解することで、組織は質を維持しながら効率的にスケールするAIワークフローを設計できます。
ルーティングが行われる前に、ルーターは受信クエリを分析します。メタデータ、タグ、クエリタイプ、複雑さ、時には意図や感情を調べます。この分析は、ルーターがリクエストを処理するのに最も適したモデルを決定できるように、コンテキストを提供します。たとえば、請求に関する顧客の質問は軽量な汎用LLMにルーティングされ、技術的なトラブルシューティングのクエリはドメイン特化型モデルに送られます。
ルーターは、以下の複数の基準に基づいて最も適切なモデルを選択します。
ドメイン専門知識:一部のLLMは特定の業界やトピックのトレーニングを受けています。
精度ニーズ:重要なタスクは、高度な推論能力を備えたモデルを必要とする場合があります。
レイテンシと速度:迅速な応答が必要な場合は、軽量モデルを使用できます。
コスト効率:高価なモデルは、高価値なクエリに取っておかれます。
これらの要因を考慮することで、ルーターは各リクエストに対して速度、精度、コストの最良のバランスを確保します。
複数のモデルが同じタスクを処理できる場合、ルーターは特定のモデルに過負荷がかからないようにクエリを知的に分配します。これにより、全体的なシステムの応答性が向上し、ピーク使用時でも安定したパフォーマンスが保証されます。
最良のモデルでさえも失敗したり、タイムアウトしたり、低信頼の応答を返したりすることがあります。ルーターはフォールバックメカニズムを実装し、自動的にクエリをバックアップモデルに再ルーティングします。これにより、ユーザーの中断なしに継続性と信頼性が確保されます。
高度なルーターは、使用パターン、モデルのパフォーマンス、クエリの結果を追跡します。これらの洞察は、チームがルーティング戦略を最適化し、より良いモデルを選択し、時間の経過とともにコストを削減するのに役立ちます。
LLMルーターは、マルチモデルAIシステムの意思決定ハブとして機能します。リクエストを分析し、適切なモデルを選択し、負荷をバランスさせ、障害を処理し、洞察を提供することで、すべてのクエリが効率的、正確、かつ信頼性を持って処理されることを保証します。この機能の組み合わせは、堅牢でスケーラブル、かつコスト効果の高いAIソリューションを{
大規模言語モデル(LLMs)は、現代のAIアプリケーションの基盤となり、チャットボットやバーチャルアシスタントから研究ツールや企業ソリューションまで、あらゆるものを支えています。しかし、すべてのLLMが同じではなく、それぞれ独自の強み、限界、およびコスト要因があります。あるものは推論に優れ、他のものは創造的な執筆、コーディング、または構造化クエリの処理に秀でています。ここで、LLMルーターが登場します。
LLMルーターは、知的な交通管理者のような役割を果たし、ユーザーのプロンプトをタスクに基づいて最も適切なモデルに自動的に誘導します。単一のモデルに頼る代わりに、企業や開発者はリアルタイムで適切なLLMにクエリをルーティングすることで、パフォーマンス、精度、およびコストを最適化できます。AIの採用が進むにつれ、LLMルーティングは、スケーラブルで信頼性が高く効率的なAIシステムを構築するための重要なレイヤーになりつつあります。
LLMルーターは、どの大規模言語モデルが各リクエストを処理すべきかを決定します。すべてのクエリを単一のモデルに送信するのではなく、入力を評価し、ルーティングロジックを適用し、最も適切なモデルに転送します。
ルーターは、コーディング関連のクエリをプログラミングに特化したモデルに誘導するような単純なルールに従ったり、分類器、埋め込み、または軽量予測モデルなどの高度な戦略を使用して、どのLLMが最良の応答を提供するかを判断することができます。
入力:ルーターは、ユーザーのクエリを受け取ります。
分析:クエリを検査し、メタデータ、タグ、タイプ、複雑さ、さらには意図や感情を確認します。これにより、リクエストの正確な要件を理解します。
モデル選択:ルーターは、ドメイン専門知識、精度、レイテンシ、コストなどの要因に基づいて最も適切なLLMを選択します。
フォールバックメカニズム:選択されたモデルが失敗、タイムアウト、または低信頼で回答を生成した場合、ルーターは信頼性を維持するために自動的にリクエストをバックアップモデルにリダイレクトします。
このアプローチは「一律に受け入れる」問題を排除します。軽量モデルはルーチンなクエリを効率的に処理し、複雑または推論に重いタスクはより能力の高いLLMに送られます。
実際には、ルーターはアプリケーションと複数のLLMの間に位置し、パフォーマンスを最適化し、コストを削減し、単一のプロバイダーへの依存を最小限に抑えます。このセットアップにより、すべてのリクエストが適切なモデルに届きながら、AIシステムが信頼性が高く柔軟であることが保証されます。
企業はますます、チャットボットやバーチャルアシスタントからコンテンツ作成やデータ分析に至るまでのタスクに対して、大規模言語モデルに頼っています。
ただし、すべてのタスクに単一のLLMを使用することは、課題を引き起こします。一部のモデルは迅速に応答しますが、深みが欠けている一方、他のモデルは高いレイテンシとコストで正確な結果を提供します。これらの違いを管理する方法がなければ、チームは常にパフォーマンス、精度、予算のトレードオフを強いられます。
LLMルーターは、タスクに最も適したモデルにリクエストを知的に誘導することでこれを解決します。
カスタマーサポートシステムは、2種類のクエリを受け取ります。
「あなたの営業時間は?」のような単純なリクエストは、高度なモデルを必要としない一方で、製品トラブルシューティングに関する複雑な技術的質問は必要です。LLMルーターなしでは、すべてのクエリが高出力の高価なモデルに送信される可能性があります。これによりコストが増加し、応答時間が遅くなります。ルーターを使用すると、単純なクエリは迅速な軽量モデルに送信され、複雑なクエリはより能力の高いLLMにルーティングされ、速度、コスト、精度が最適化されます。
最適化されたパフォーマンス:クエリの複雑さに合ったモデルをマッチングします。
コスト効率:ルーチンなタスクに高価なモデルを過剰使用するのを避けます。
信頼性:フォールバックメカニズムは、モデルが失敗した場合でも一貫した応答を保証します。
柔軟性:ベンダーロックインを避けるために、異なるプロバイダーからのモデルを組み合わせます。
スケーラビリティ:増加するクエリボリュームと負荷分散を効率的に管理します。
知的にクエリをルーティングすることで、企業は迅速で、より正確で、コスト効率の良いAIサービスを提供します。LLMルーターは、AIの展開を一律のアプローチから柔軟で信頼性が高く効率的なシステムに変革し、現代のAIインフラにとって欠かせない存在にしています。
LLMルーターは単なる交通指導者以上のものであり、AIシステムをよりスマートで迅速かつ信頼性のあるものにするためのいくつかのコア機能を提供します。これらの機能を理解することで、組織は質を維持しながら効率的にスケールするAIワークフローを設計できます。
ルーティングが行われる前に、ルーターは受信クエリを分析します。メタデータ、タグ、クエリタイプ、複雑さ、時には意図や感情を調べます。この分析は、ルーターがリクエストを処理するのに最も適したモデルを決定できるように、コンテキストを提供します。たとえば、請求に関する顧客の質問は軽量な汎用LLMにルーティングされ、技術的なトラブルシューティングのクエリはドメイン特化型モデルに送られます。
ルーターは、以下の複数の基準に基づいて最も適切なモデルを選択します。
ドメイン専門知識:一部のLLMは特定の業界やトピックのトレーニングを受けています。
精度ニーズ:重要なタスクは、高度な推論能力を備えたモデルを必要とする場合があります。
レイテンシと速度:迅速な応答が必要な場合は、軽量モデルを使用できます。
コスト効率:高価なモデルは、高価値なクエリに取っておかれます。
これらの要因を考慮することで、ルーターは各リクエストに対して速度、精度、コストの最良のバランスを確保します。
複数のモデルが同じタスクを処理できる場合、ルーターは特定のモデルに過負荷がかからないようにクエリを知的に分配します。これにより、全体的なシステムの応答性が向上し、ピーク使用時でも安定したパフォーマンスが保証されます。
最良のモデルでさえも失敗したり、タイムアウトしたり、低信頼の応答を返したりすることがあります。ルーターはフォールバックメカニズムを実装し、自動的にクエリをバックアップモデルに再ルーティングします。これにより、ユーザーの中断なしに継続性と信頼性が確保されます。
高度なルーターは、使用パターン、モデルのパフォーマンス、クエリの結果を追跡します。これらの洞察は、チームがルーティング戦略を最適化し、より良いモデルを選択し、時間の経過とともにコストを削減するのに役立ちます。
LLMルーターは、マルチモデルAIシステムの意思決定ハブとして機能します。リクエストを分析し、適切なモデルを選択し、負荷をバランスさせ、障害を処理し、洞察を提供することで、すべてのクエリが効率的、正確、かつ信頼性を持って処理されることを保証します。この機能の組み合わせは、堅牢でスケーラブル、かつコスト効果の高いAIソリューションを{
AIルーティング技術
By アンドリュー・ジェン •

エンタープライズLLMルーティングの複雑さを管理する
エンタープライズLLMルーティングの複雑さを管理する

AIモデルのトークン使用量を追跡する
AIモデルのトークン使用量を追跡する

OneRouter アンスロポシック クロード API
OneRouter アンスロポシック クロード API
